Modelagem Dimensional — Como foi feito (explicado fácil)
Imagine sua casa toda bagunçada: o garfo no banheiro, o sapato na geladeira. Você até acha as coisas, mas demora. Modelagem dimensional é arrumar essa casa pra que qualquer pessoa encontre o que precisa em segundos — só que com dados.
O que é isso, em uma frase?
Um e-commerce guarda os dados de pedidos espalhados em 8 tabelas diferentes (clientes aqui, produtos ali, pedidos lá). Isso é ótimo pra registrar uma compra, mas péssimo pra analisar — toda pergunta vira um quebra-cabeça com 8 peças.
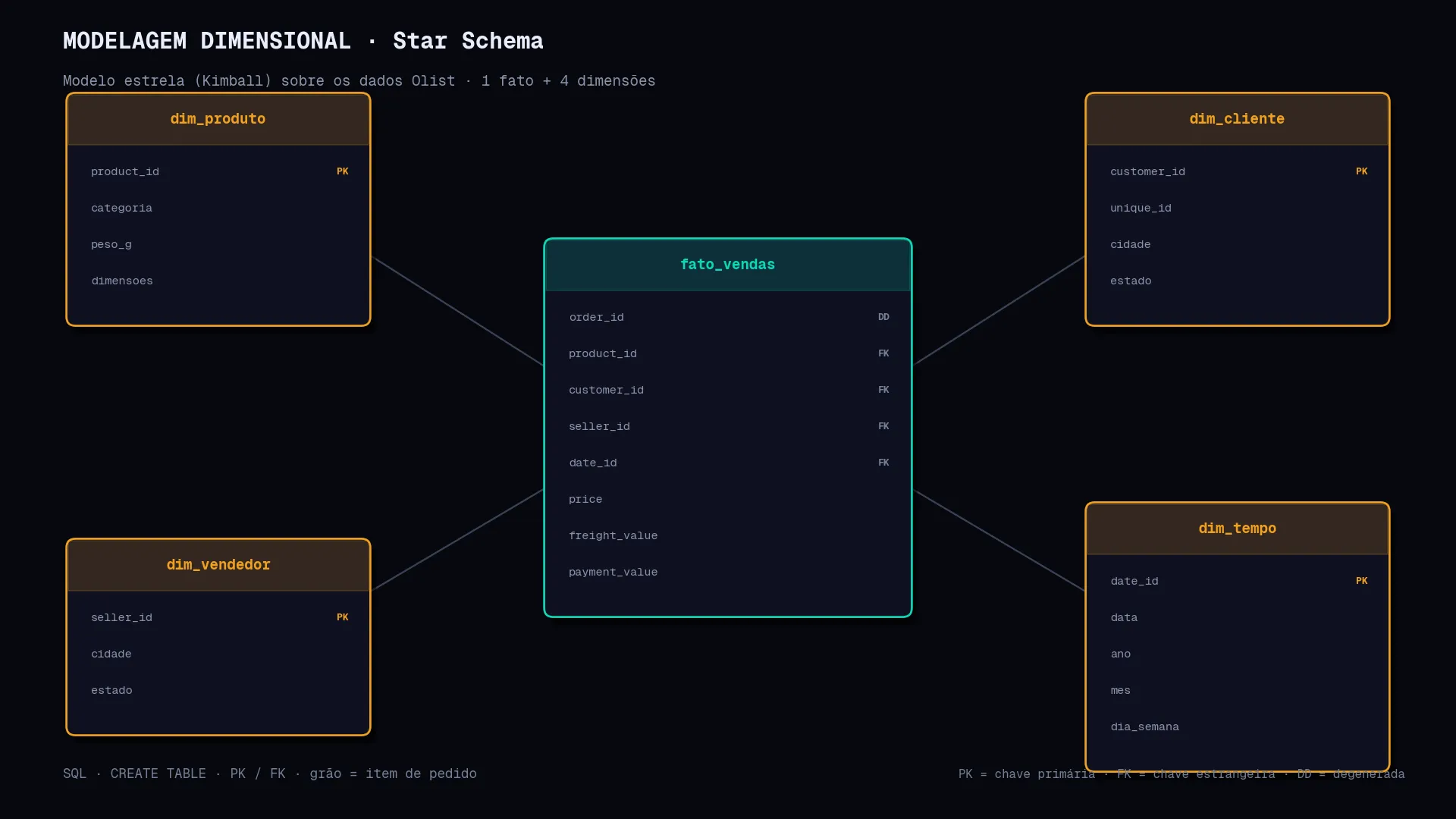
Aqui eu reorganizei tudo num "modelo estrela" (em inglês, star schema): no centro fica uma tabela única chamada fato, e em volta dela orbitam tabelas menores chamadas dimensões. Vai parecer estranho no início, mas a mágica acontece quando você precisa fazer uma pergunta — ela passa a ter resposta em 1 ou 2 passos em vez de 8.
Por que isso importa? Porque dashboards do Power BI, do Looker, do Metabase... todos esperam dados organizados nesse formato. Quem sabe modelar bem, faz BI rodar rápido.
Do caos à estrela
1 · Decidir o "grão". Antes de criar qualquer tabela, a pergunta mais importante: o que UMA linha da minha tabela principal vai representar?. Pedido inteiro? Item de pedido? Item por dia? Aqui escolhi "um item de um pedido" — é o nível mais fino e dá pra "subir" agregando depois. Essa decisão dita tudo.
2 · Criar as dimensões — os "personagens" da história. Cada coisa que você quer filtrar ou agrupar por vira uma dimensão. Quem comprou? dim_cliente. O quê? dim_produto. Quando? dim_tempo. Quem vendeu? dim_vendedor.
CREATE TABLE dim_produto (
product_id TEXT PRIMARY KEY,
categoria TEXT,
peso_g INTEGER,
-- ... outros atributos do produto
);
Repare: a dimensão guarda tudo o que descreve um produto. Quando você quiser perguntar "vendas por categoria", é só dar um JOIN com essa tabelinha. Sem mistério.
3 · Criar o fato — a tabela do "evento". Aqui ficam os números (preço, frete) e as chaves que ligam às dimensões. Pensa assim: cada linha do fato é uma frase tipo "Cliente X comprou o produto Y do vendedor Z no dia W por R$ 99".
CREATE TABLE fato_vendas (
order_id TEXT,
product_id TEXT REFERENCES dim_produto(product_id),
customer_id TEXT REFERENCES dim_cliente(customer_id),
seller_id TEXT REFERENCES dim_vendedor(seller_id),
date_id INTEGER REFERENCES dim_tempo(date_id),
price NUMERIC,
freight_value NUMERIC,
PRIMARY KEY (order_id, order_item_id)
);
As palavras REFERENCES são promessas: "esse customer_id existe na dim_cliente". Se alguém tentar gravar um cliente que não existe, o banco recusa. É integridade automática.
4 · Encher de dados. Pego os dados das 8 tabelas originais e copio pras minhas tabelas novas, já no formato certo. Depois conto pra ver se tá tudo lá:
| tabela | linhas |
|---|---|
| dim_produto | 32.951 |
| dim_cliente | 99.441 |
| dim_vendedor | 3.095 |
| dim_tempo | 615 (dias distintos) |
| fato_vendas | 110.197 (itens entregues) |
5 · Provar que valeu a pena. A prova final: rodar a mesma pergunta nos dois jeitos e ver a diferença. "Quais 5 estados venderam mais?":
-- ANTES (8 tabelas, 3 JOINs, lendo várias): SELECT cu.customer_state, SUM(i.price) FROM olist_order_items_dataset i JOIN olist_orders_dataset o ON o.order_id = i.order_id JOIN olist_customers_dataset cu ON cu.customer_id = o.customer_id WHERE o.order_status = 'delivered' GROUP BY cu.customer_state ORDER BY 2 DESC LIMIT 5; -- DEPOIS (1 JOIN, lê quase nada, mesmo resultado): SELECT c.estado, SUM(f.price) FROM fato_vendas f JOIN dim_cliente c ON c.customer_id = f.customer_id GROUP BY c.estado ORDER BY 2 DESC LIMIT 5;
| estado | receita |
|---|---|
| SP | R$ 5.068.000 |
| RJ | R$ 1.760.000 |
| MG | R$ 1.552.000 |
| RS | R$ 729.000 |
| PR | R$ 666.000 |
Mesma resposta, query 3× mais curta. Multiplica isso por 100 análises diferentes e você economiza horas, e o pessoal do negócio passa a entender o que tá rodando.
A estrela em forma de diagrama
Em uma linha: o que esse projeto ensina
Que organização vale ouro. Gastar 1 dia modelando bem economiza meses de queries lentas e análises confusas depois. É o tipo de trabalho invisível — ninguém aplaude, mas todo dashboard que funciona bem tem isso por trás.
Coisas técnicas que apareceram aqui: CREATE TABLE com PRIMARY KEY e FOREIGN KEY (REFERENCES), INSERT ... SELECT, modelagem Kimball, definição de grão, dimensão degenerada, chave artificial (date_id).