Predição de Empregabilidade Estudantil
Um modelo que identifica precocemente estudantes em risco de não conseguir colocação — para que a instituição possa agir antes, e não depois.
O problema
Identificar cedo quais estudantes têm maior risco de não se colocar no mercado permite direcionar mentoria e apoio a quem mais precisa. O desafio é fazer essa previsão a partir do histórico acadêmico, antes do desfecho.
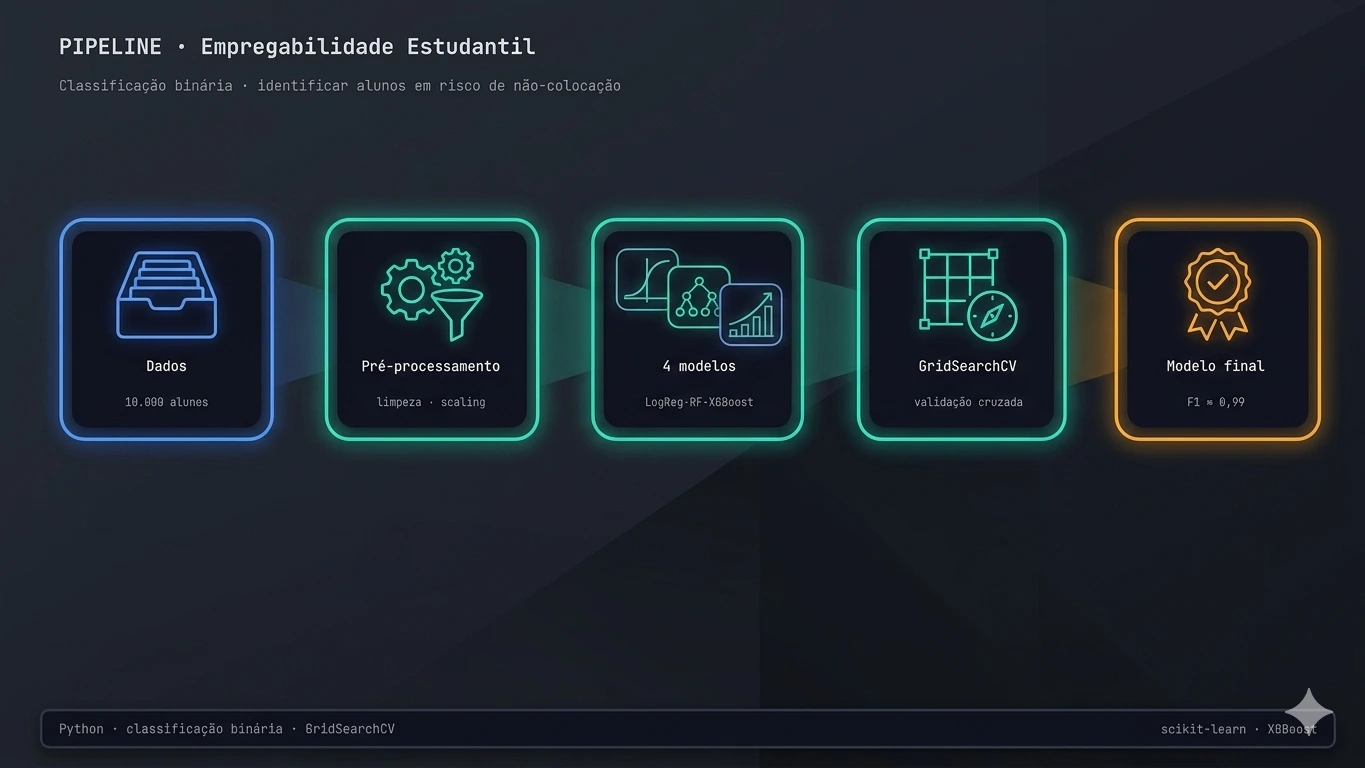
Trabalhei sobre uma base de 10.000 alunos, tratando o problema como uma classificação binária: colocado vs. não colocado.
A abordagem
Após limpeza e padronização (scaling) das variáveis, comparei quatro algoritmos — Regressão Logística, Árvore de Decisão, Random Forest e XGBoost — sob validação cruzada. Os hiperparâmetros foram ajustados com GridSearchCV, e o modelo final avaliado por F1 e classification report.
Pipeline