Detecção de Fraudes em Cartão de Crédito
Análise exploratória e modelo de classificação sobre 1,3 milhão de transações de cartão — identificando onde a fraude se concentra num cenário de classes fortemente desbalanceadas.
O problema
Fraude em cartão é um evento raro: numa base pública de 1.296.675 transações, apenas 0,58% são fraudulentas. Esse desbalanceamento extremo é justamente o que torna o problema difícil — um modelo ingênuo que "chuta tudo legítimo" acerta 99,4% e mesmo assim é inútil.
O objetivo foi entender onde a fraude se concentra e treinar um modelo capaz de separar o sinal do ruído sem se deixar enganar pela maioria.
A abordagem
Com Python e Pandas, fiz a leitura e o pré-processamento das transações, seguidos de uma análise exploratória (EDA) por categoria, valor e tempo. Depois, treinei um modelo de classificação com scikit-learn, tratando o desbalanceamento das classes e avaliando o desempenho em base de teste separada.
A EDA por categoria foi o passo mais revelador — é o que está no gráfico abaixo.
Onde a fraude se concentra
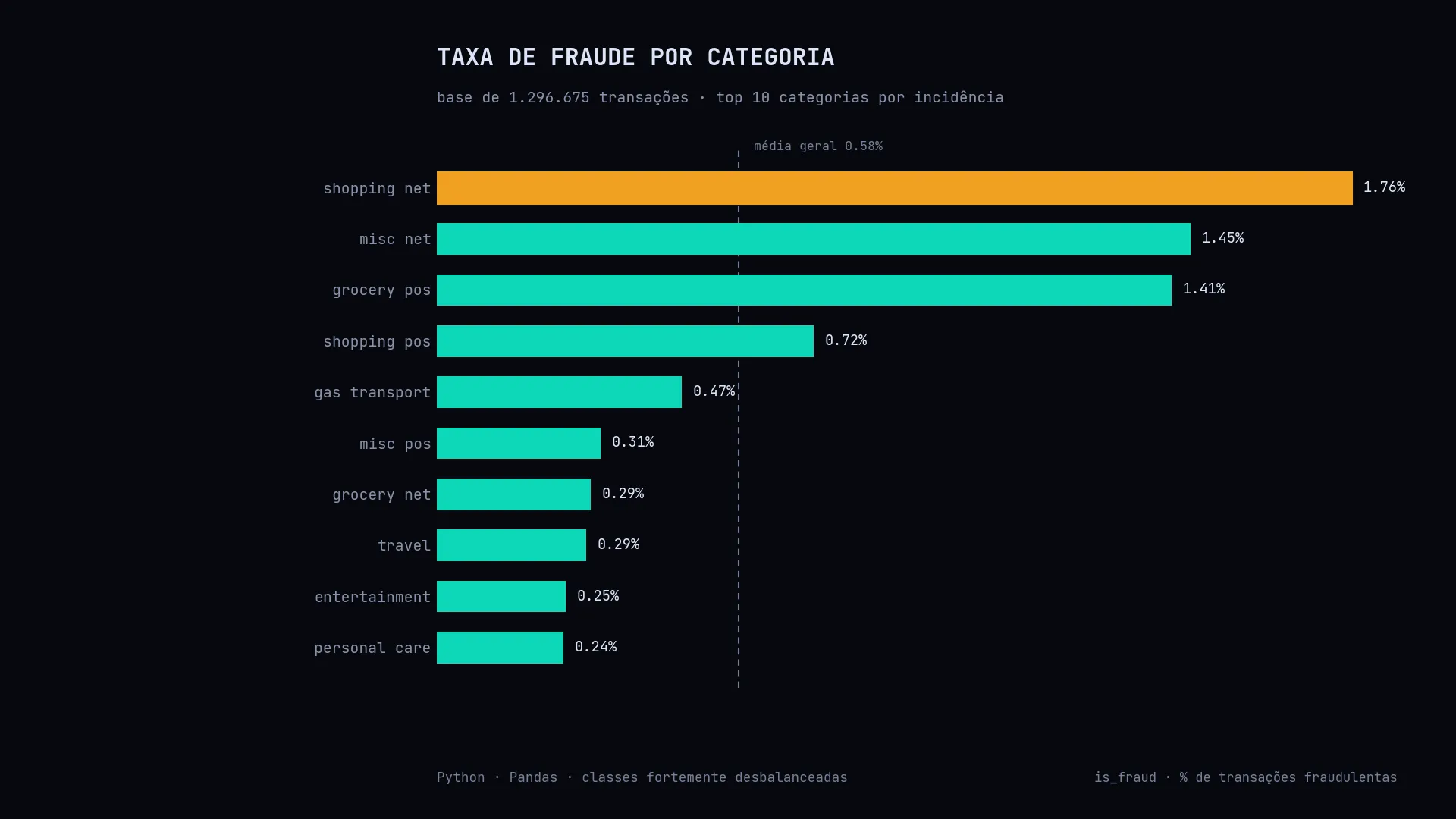
shopping_net, misc_net) concentram as maiores taxas de fraude — bem acima da média geral.