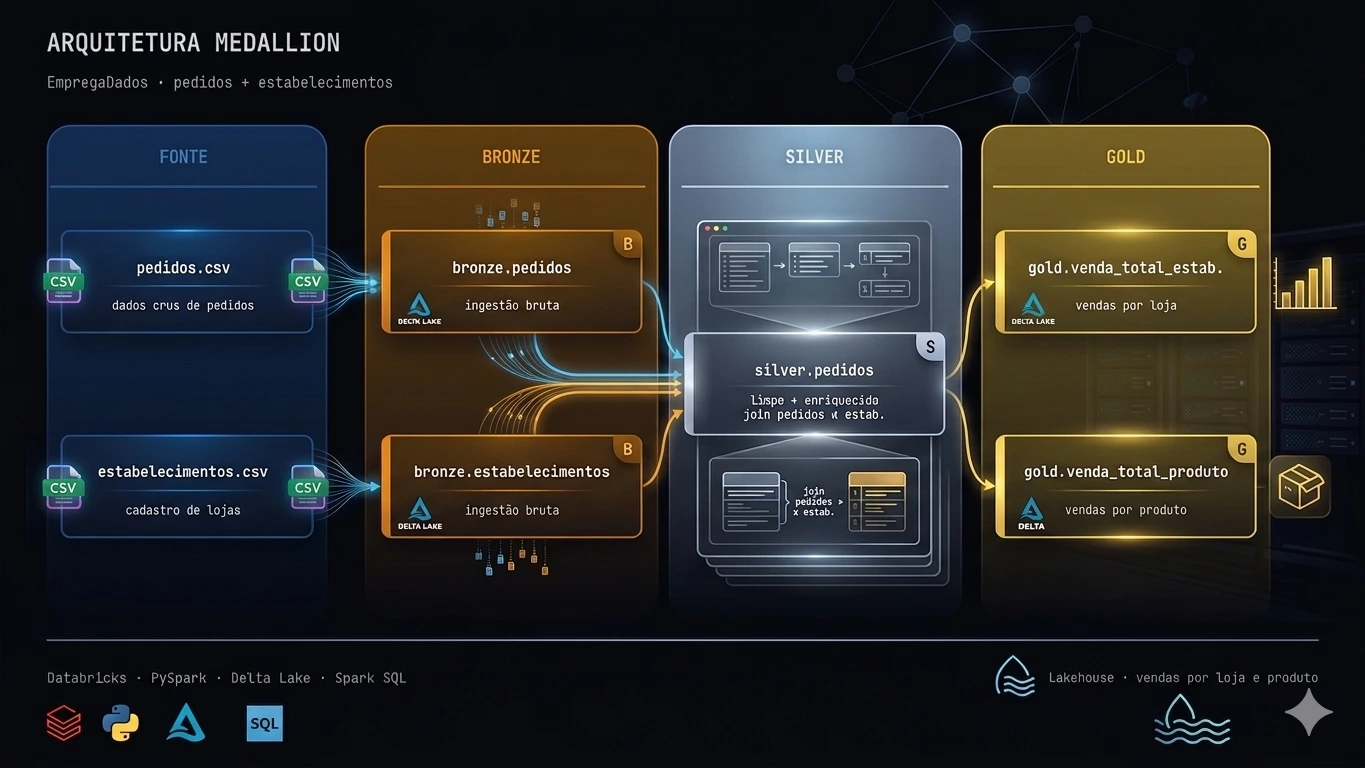
Pipeline Medallion — EmpregaDados
Implementação de uma arquitetura medallion (Bronze → Silver → Gold) no Databricks com PySpark e Delta Lake, transformando dados crus de pedidos e estabelecimentos em tabelas analíticas de vendas.
O problema
Dados crus de pedidos e estabelecimentos (em CSV) não servem diretamente para análise: faltam limpeza, padronização e o cruzamento entre as fontes. Sem uma camada organizada, qualquer pergunta de negócio — vendas por loja, por produto — exige retrabalho.
O objetivo foi estruturar esses dados num lakehouse, de forma escalável e versionada, até chegar a tabelas prontas para consumo analítico.
A solução
Implementei a arquitetura medallion em três camadas no Databricks, com PySpark e tabelas Delta Lake:
Bronze — ingestão bruta dos CSVs em bronze.pedidos e bronze.estabelecimentos, preservando os dados como chegaram.
Silver — limpeza e enriquecimento em silver.pedidos, fazendo o join entre pedidos e estabelecimentos e tratando tipos e valores.
Gold — agregações de negócio: gold.venda_total_estabelecimentos (vendas por loja) e gold.venda_total_produto (vendas por produto), prontas para BI.
Arquitetura