BanVic Analytics — Engenharia de Dados Completa
Versao revisada do Desafio Lighthouse 2024: desta vez com pipeline ETL em SQL (schema stg_banvic no PostgreSQL), camada de staging antes do Power BI, e integracao com dados externos de IPCA — o que faltou na primeira entrega.
O desafio
O BanVic e um banco ficticio criado pela Lighthouse para o desafio de Engenharia de Analytics 2024. O objetivo: consolidar seis fontes de dados — clientes, colaboradores, agencias, contas, propostas de credito e transacoes — em uma visao analitica acionavel.
O desafio incluia o uso de dados externos para enriquecer a analise (o IPCA era explicitamente sugerido) e a implementacao de uma camada de staging antes do BI, garantindo governanca de dados.
A primeira versao foi reprovada por dois gaps: transformacoes feitas diretamente no Power Query sem ETL previo, e ausencia de dados externos. Esta versao corrige ambos.
Da v1 a versao revisada
Gap 1 — Sem ETL: a primeira versao conectava o Power BI diretamente nos arquivos CSV, fazendo todas as transformacoes no Power Query. Em ambientes de producao isso cria dependencia da ferramenta de BI para governanca e dificulta o reaproveitamento dos dados. A versao revisada implementa um pipeline ETL Medallion (Bronze → Silver → Gold) em Python + Pandas, com parquet em cada camada, 8 data quality checks automatizados e logging estruturado. Os dados chegam ja tratados a dois caminhos de consumo: Power BI via stg_banvic (PostgreSQL) ou Dashboard Web V2 via JSON.
Gap 2 — Sem dado externo: o proprio enunciado do desafio sugeria o uso do IPCA para correlacionar comportamento dos clientes com variacoes macroeconomicas. A sub-pagina IPCA mostra essa analise: volume de saques vs. inflacao mensal, propostas de credito em periodos de alta inflacao, e juros do banco vs. IPCA acumulado (19,11% no periodo 2020–2022).
Bonus — dim_dates: a Gold tambem gera uma dimensao temporal derivada (trimestre, dia-da-semana, mes com/sem “R”, par/impar) usada na pagina de Padroes Temporais. E essa mesma logica que identifica o dump artificial de fim de 2022 (dias com mais de 200 transacoes) e o exclui das analises de sazonalidade.
Arquitetura
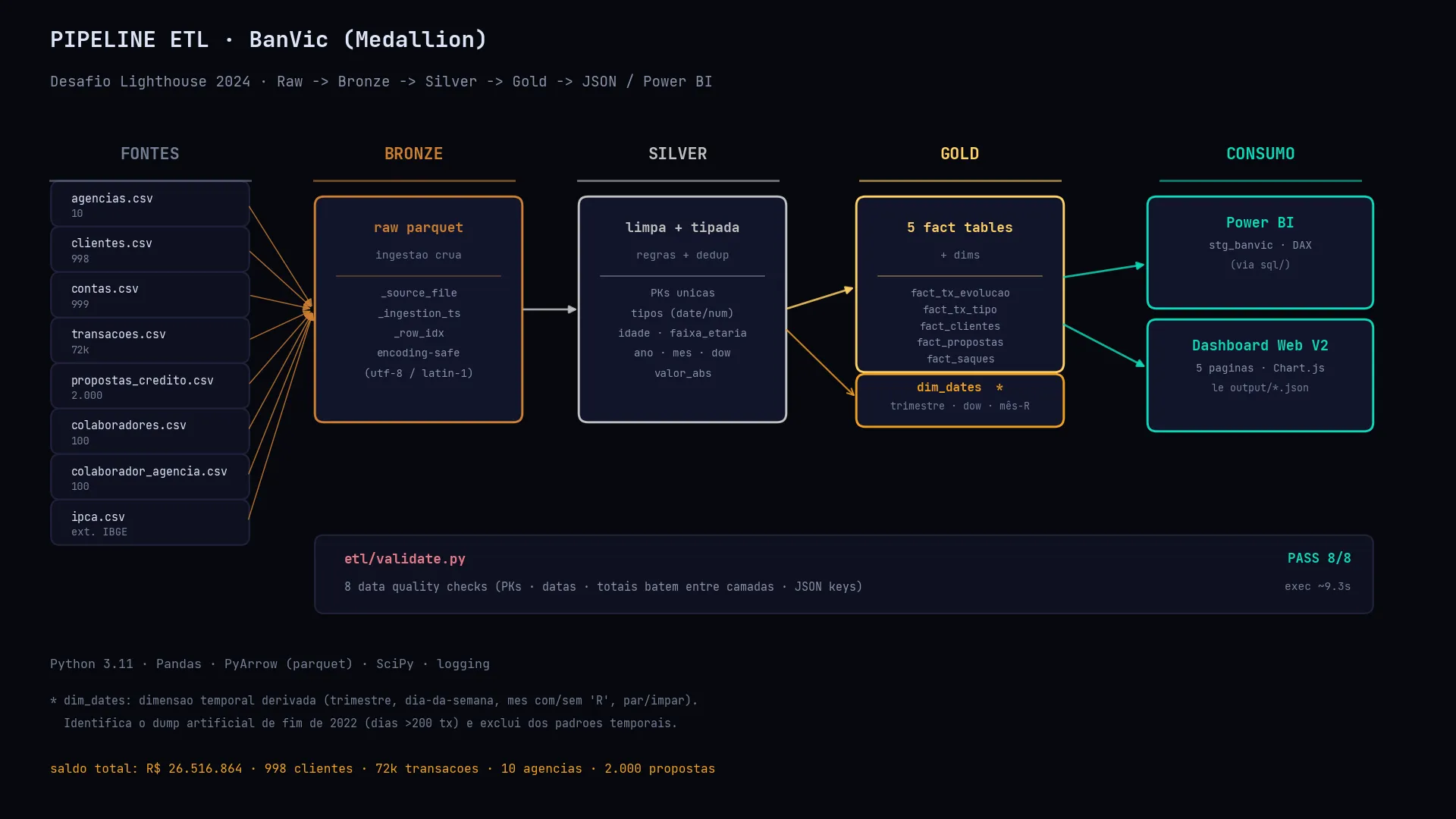
dim_dates → consumo via Power BI ou Dashboard Web V2. Validacao automatica: 8 data quality checks.Metricas reais
Aprofunde em cada frente
Cada frente de analise tem sua propria pagina com graficos, metricas e insights especificos.
Analises temporais com dim_dates
O desafio pedia uma dimensao de datas (dim_dates) para sustentar o Data Warehouse. Construi a tabela (1 linha por dia — trimestre, mes, dia da semana, mes com/sem “R”, par/impar) e a usei para responder as perguntas de negocio.
Tratamento honesto: as transacoes de 29 e 30/12/2022 concentram um dump artificial de ~20 mil registros (vs. ~12/dia normais). Esses dias foram excluidos das analises de padrao temporal — senao Q4, dezembro e sexta-feira ficariam falsamente inflados.